Creating a Neural Network¶
This chapter describes how to create a feed forward or recurrent neural network in pyrenn.
Feed forward neural networks in pyrenn¶
pyrenn allows to create multilayer perceptron (MLP) neural networks. A MLP is a feedforward artificial neural network, that is defined by:
- an input layer with \(R\) inputs
- \(M-1\) hidden layers, where each layer \(m\) has an abritary number of neurons \(S^\text{m}\)
- and an output layer with \(S^\text{M}\) number of neurons, which corespond to the number of outputs of the neural network
The following notation allows n short description of an MLP which gives the number of inputs \(R\), the number of layers \(M\) and the number of neurons \(S^\text{m}\) in each layer \(m\):
In a MLP each layer has a full connection to the next layer, which means that each neuron output in layer \(m\) is an input to each neuron in layer \(m+1\) (and inputs are connected to all neurons in the first layer).
figure 1 shows an example of a MLP with 2 inputs, two hidden layers with two neurons each and an output layer with one neuron (and therefore one output \(\hat{y}\)). The MLP can be described with
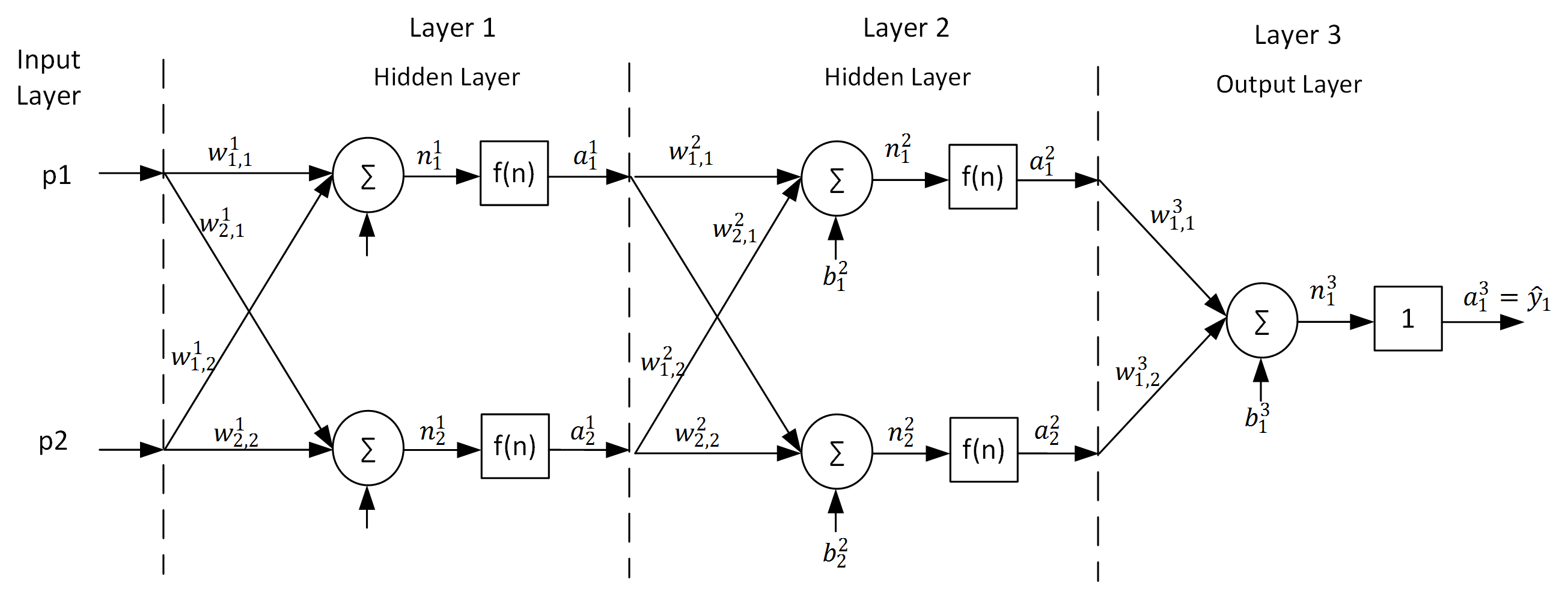
Figure 1: A \([2\; 2\; 2\; 1]\) MLP
The MLP in figure 1 consists of 5 neurons. The structure of a neuron is shown in figure 2.
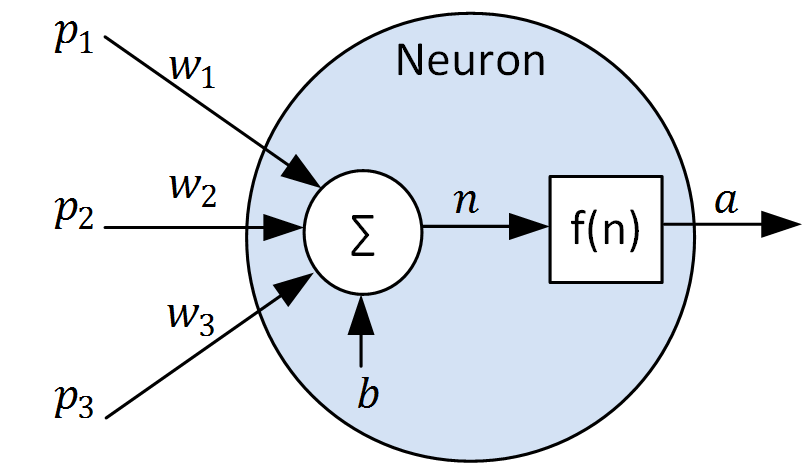
Figure 2: Structure of a neuron
Neurons are the constitutive units in an artificial neural network. They can have several inputs \(p\) which are multiplied by the connection weights \(w\) and summed up together with the bias weight \(b\) to the summation output \(n\). Then the neuron output \(a\) is calculated using the transfer function (also activation function) \(f(n)\).
Note
Generally different transfer function could be used in a neural network. In pyrenn the transferfunction is defined as:
- the hyperbolic tangent \(a=tanh(n)\) for all neurons in hidden layers
- the linear function \(y=a=n\) for all neurons in the output layer
The array-matrix illustration allows a clearer description of a MLP. Therefore the inputs \(p\), the neural network outputs \(\hat{y}\), the summation outputs \(n\) , the layer outputs \(a\), the transfer functions \(f(n)\) and the bias weights \(b\) of one layer \(m\) are represented by the arrays \(\underline{p},\:\underline{\hat{y}},\:\underline{n}^m,\:\underline{a}^m,\:\underline{f}^m,\:\underline{b}^m\) (the upper index represents the layer \(m\): and the lower index the number of the neuron or input).
\[\begin{split}\underline{p} = \begin{bmatrix} p_1\\ ...\\ p_R\\ \end{bmatrix}\: \underline{\hat{y}}= \begin{bmatrix} {\hat{y}}_1\\ ...\\ {\hat{y}}_{S^M}\\ \end{bmatrix}\: \underline{n}^m= \begin{bmatrix} {n}^m_1\\ ...\\ {n}^m_{S^m}\\ \end{bmatrix}\: \underline{a}^m= \begin{bmatrix} {a}^m_1\\ ...\\ {a}^m_{S^m}\\ \end{bmatrix}\: \underline{f}^m= \begin{bmatrix} {f}^m_1\\ ...\\ {f}^m_{S^m}\\ \end{bmatrix}\: \underline{b}^m= \begin{bmatrix} {b}^m_1\\ ...\\ {b}^m_{S^m}\\ \end{bmatrix}\end{split}\]
The connection weights \(w\) are represented by the matrix \(\widetilde{IW}^{1,1}\) which contains the connection weights of the first layer and the matrices \(\widetilde{LW}^{m,l}\), which contain the weights that connect the outputs of layer \(l\) with layer \(m\). For the example in figure 1 the connection matrices are:
\[\begin{split}\widetilde{IW}^{1,1}= \begin{bmatrix} w^1_{1,1} & w^1_{1,2} \\ w^1_{2,1} & w^1_{2,2} \end{bmatrix}\; \widetilde{LW}^{2,1}= \begin{bmatrix} w^2_{1,1} & w^2_{1,2} \\ w^2_{2,1} & w^2_{2,2} \end{bmatrix}\; \widetilde{LW}^{3,2}= \begin{bmatrix} w^3_{1,1} & w^3_{1,2} \\ w^3_{2,1} & w^3_{2,2} \end{bmatrix}\end{split}\]
figure 3 shows the array-matrix illustration of the MLP of figure 1 :
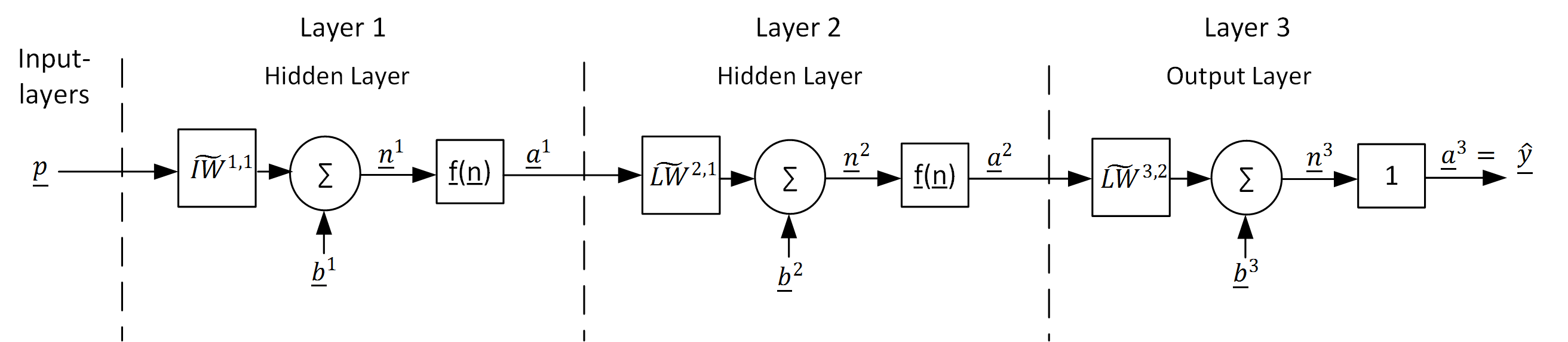
Figure 3: Array-matrix illustration of a MLP with two hidden layers
Recurrent neural networks in pyrenn¶
pyrenn allows also to define different topologies of recurrent neural networks, which are networks, where connections between units form a directed cycle. In pyrenn this is implemented by connecting the output of a layer \(m\) with the input of previous layers \(<m\) or with it’s own layer input. Since this would lead to an infeasible system, a real-valued time-delay has to be applied to the recurrent connections. This is done by so called Tapped Delay Lines (TDL). A TDL contains delay operators \(z^{-d}\) which delay time-discrete signals by a real-valued delay \(d\). To describe the delay elements in a TDL, the Sets \({DI}^{l,m}\) and \({DL}^{l,m}\) are introduced. They contain all real-valued delays \(d_i\) between a connection from the output of layer \(l\) to the input of layer \(m\). Consequently for every \(d_i \in {DI}^{l,m}\) or \(d_i \in {DL}^{l,m}\) there has to be a connection matrix \(\widetilde{IW}^{m,l}[d_i]\) or \(\widetilde{LW}^{m,l}[d_i]\). figure 4 shows the detailed and simplified illustration a TDL example.
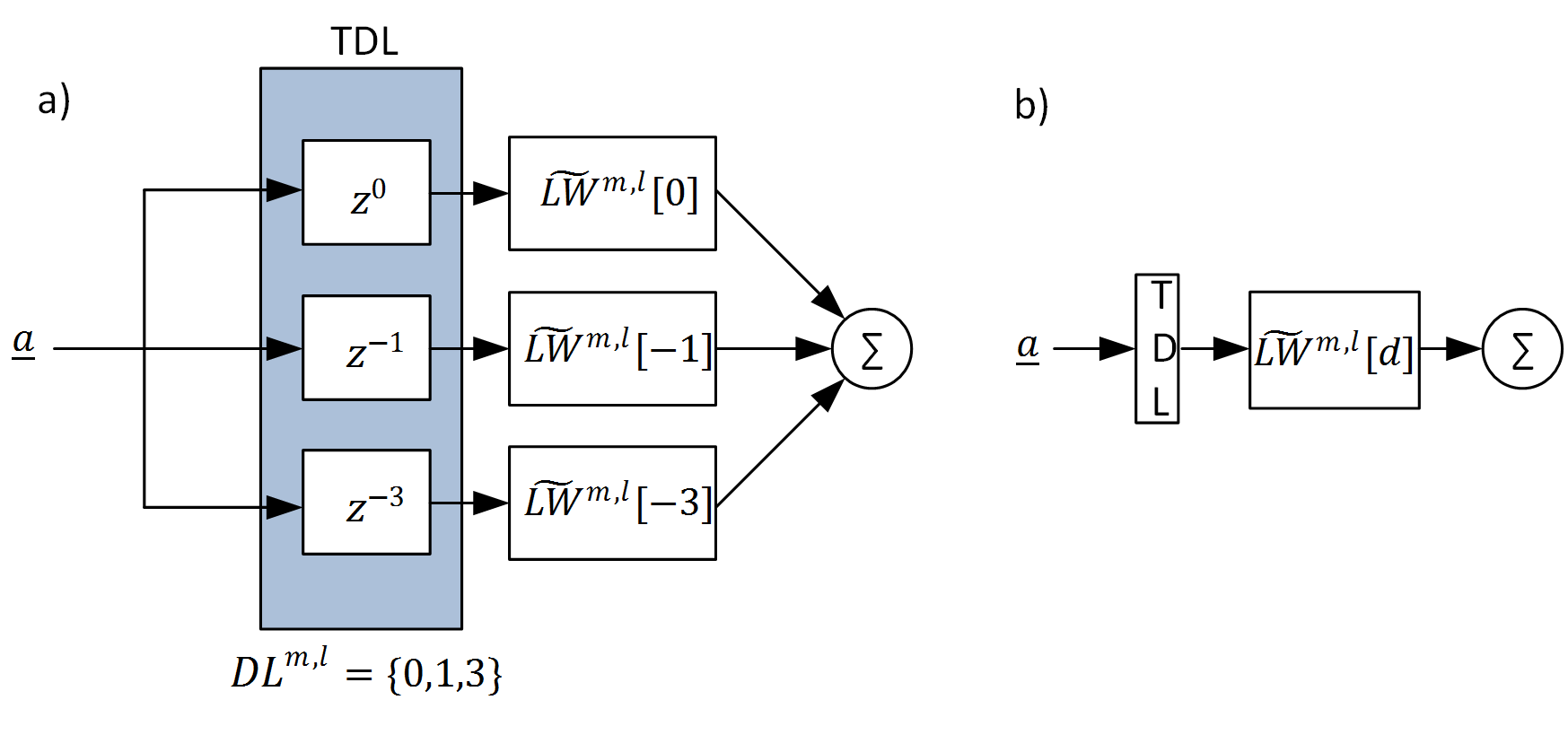
Figure 4: TDL in detailed (a) and simplified (b) illustration
With pyrenn it is possible to define three different types of TDLs, which will add (recurrent) time-delayed connections with their weight matrices to the MLP. The influence of these setting on the neural network structure is explained with the help of figure 5.
Input delays \(dIn \in [0,1,2,...]\) (blue; default for MLP \(dIn=[0]\)):
This allows to delay the inputs \(\underline{p}\) of the neural network by any real-valued time-step \(d \geq 0\). Thereby the neural network can be used for systems where the output depends not only on the current input, but also previous inputs. \(dIn\) has to be non-empty, otherwise no inputs are connected with the neural network! When the current input should be used in the neural network, \(dIn\) hast to contain 0. Since this only delays the inputs, this will not lead to a recurrent network.
\[{DI}^{1,1} = dIn\]Output delays \(dOut \in [1,2,...]\) (green; default for MLP \(dOut=[]\)):
This allows to add a recurrent connection of the outputs \(\underline{\hat{y}}\) of the neural network to it’s first layer (which is similar to a recurrent connection of the output of the network to it’s input). Thereby the neural network can be used for systems where the output depends not only on the inputs, but also on prevoius outputs (states). Since this adds a recurrent connection if \(dIn\) is non-empty, the delays has to be greater than zero \(d>0\). A neural network with such a connection will be a recurrent neural network.
\[{DL}^{1,M} = dOut\]Internal delays \(dIntern \in [1,2,...]\) (red; default for MLP \(dOut=[]\)):
This allows to add a recurrent connection from all layers to all previous layers and to it self (except from the output layer to the first layer). Thereby the neural network can be used for systems where the output depends on prevoius internal states. Since this adds recurrent connections if \(dIntern\) is non-empty, the delays has to be greater than zero \(d>0\). A neural network with such a connection will be a recurrent neural network.
\[{DL}^{m,l} = dIntern \;\;\;\;\forall (m \leq l|\; {DL}^{m,l} \neq {DL}^{1,M})\]
In pyrenn all forward connections (except the inputs) only have un-delayed direct connections!
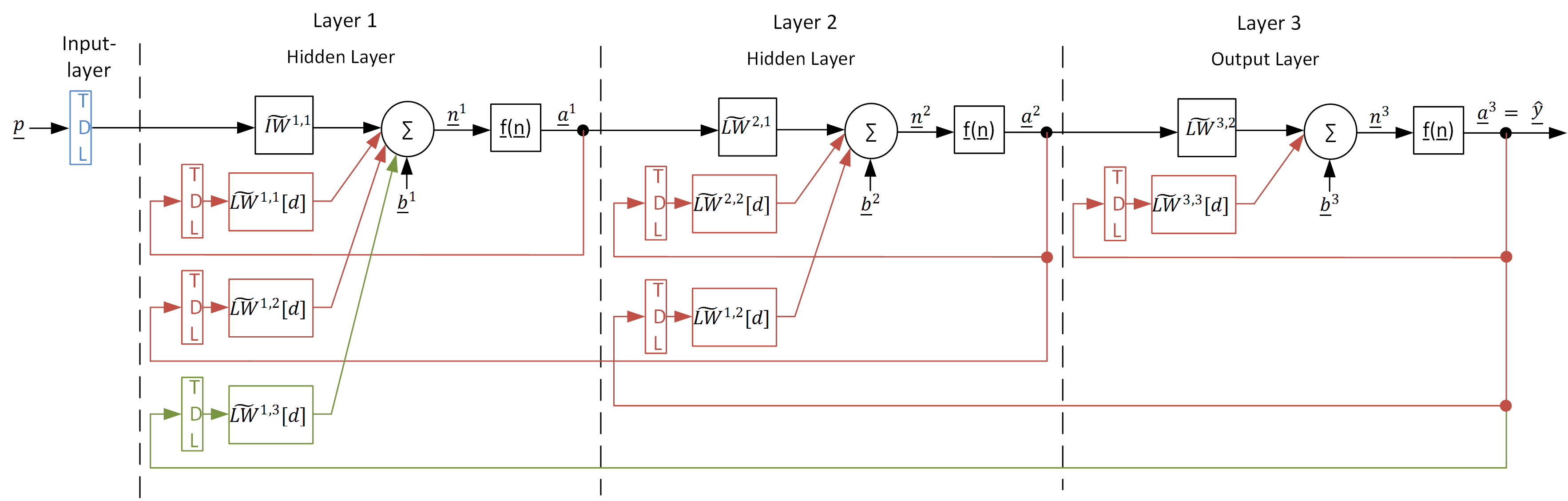
Figure 5: Possible delayed and recurrent connections that can be created with pyrenn for a neural network with two hidden layers.
Note
With the described definitions, every neural network in pyrenn can be defined by only four parameters:
- The short notation \(nn\) which describes the number of inputs, layers, neurons and outputs
- the input delays \(dIn\) of the neural network
- the output delays \(dOut\) of the neural network
- the internal delays \(dIntern\) of the neural network
Creating a neural network with CreateNN()¶
The function CreateNN creates a pyrenn neural network object that can be trained and used. When only the short notation \(nn\) is given as input, the created neural network will be a MLP with no delayed connections. If a (recurrent) neural network with delays should be created, the parameters \(dIn\), \(dIntern\) and/or \(dOut\) have to be secified as described above. In the Examples different neural network topologies are created.
Python¶
-
pyrenn.CreateNN(nn, [dIn=[0],dIntern=[ ], dOut=[ ]])¶ Creates a neural network object with random values between -0.5 and 0.5 for the weights.
Parameters: - nn (list) – short notation of the neural network \([R\; S^\text{1}\; S^\text{2}\; ...\; S^\text{M}]\)
- dIn (list) – Set of input delays of the neural network
- dIntern (list) – Set of inernal delays of the neural network
- dOut (list) – Set of output delays of the neural network
Returns: a pyrenn neural network object
Return type:
Matlab¶
-
CreateNN(nn, [dIn=[0], dIntern=[ ], dOut=[ ]])¶ Creates a neural network object with random values between -0.5 and 0.5 for the weights.
Parameters: - nn (array) – short notation of the neural network \([R\; S^\text{1}\; S^\text{2}\; ...\; S^\text{M}]\); size [1 x M+1]
- dIn (array) – Set of input delays of the neural network; size [1 x X]
- dIntern (array) – Set of itnernal delays of the neural network; size [1 x X]
- dOut (array) – Set of output delays of the neural network; size [1 x X]
Returns: a pyrenn neural network object
Return type: struct